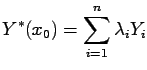If ![]() and
and ![]() are known, then
we can define a new variable
are known, then
we can define a new variable ![]() with zero mean:
with zero mean:
| 0 |
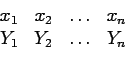
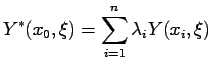
![$\displaystyle E[(\sum_{i=1}^n \lambda_i Y_i - Y_0)^2]$](img292.gif) |
|||
![$\displaystyle E[(\sum_{i=1}^n \lambda_i Y_i - Y_0)(\sum_{i=1}^n \lambda_i Y_i - Y_0)]$](img293.gif) |
|||
![$\displaystyle E[(\sum_{i=1}^n \lambda_i Y_i)(\sum_{i=1}^n \lambda_i Y_i)]
- 2 E[\sum_{i=1}^n \lambda_i Y_i Y_0] + E[Y_0^2]$](img294.gif) |
|||
![$\displaystyle \sum_{i=1}^n\sum_{j=1}^n \lambda_i\lambda_j E[Y_iY_j]
- 2 \sum_{i=1}^n E[Y_iY_0] + E[Y_0^2]$](img295.gif) |
![\begin{multline*}
E[(Y(x_0) - Y^\ast(x_0))^2] =
\sum_{i=1}^n\sum_{j=1}^n \lamb...
...da_j C(x_i-x_j)
- 2 \sum_{i=1}^n \lambda_i C(x_i-x_0) \ +C(0)
\end{multline*}](img299.gif)
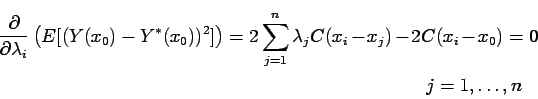
![$\displaystyle C = \left[ \begin{array}{cccc}
C(0) & C(x_1-x_2) & \ldots & c(x_1...
...& \cdot \\
\cdot & & \cdot & \\
C(x_n-x_1) & & & C(0) \\
\end{array}\right]
$](img303.gif)
![$\displaystyle b = \left[ \begin{array}{c}
C(x_1-x_0) \\
\cdot \\
\cdot \\
\cdot \\
C(x_n-x_0) \\
\end{array}\right]
$](img305.gif)
Matrix ![]() is the spatial covarianve matrix and does not depend upon
is the spatial covarianve matrix and does not depend upon
![]() . It can be shown that if all the
. It can be shown that if all the ![]() 's are
distinct then
's are
distinct then ![]() is positive definite, and thus the linear
system (2.5) can be solved with either direct or
iterative methods. Once the solution vector
is positive definite, and thus the linear
system (2.5) can be solved with either direct or
iterative methods. Once the solution vector ![]() is obtained,
equation (2.4) yields the estimation of our
regionalized variable at point
is obtained,
equation (2.4) yields the estimation of our
regionalized variable at point ![]() . Thus the calculated value
for
. Thus the calculated value
for ![]() is actually function of the estimation point
is actually function of the estimation point ![]() .
If we want to change the estimation point
.
If we want to change the estimation point
![]() , for example if we need to obtain a spatial distribution
of our regionalized variable, we need to solve the linear
system (2.5) for different values of
, for example if we need to obtain a spatial distribution
of our regionalized variable, we need to solve the linear
system (2.5) for different values of ![]() . In this case
it is convenient to factorize matrix
. In this case
it is convenient to factorize matrix ![]() using Cholseky
decomposition and then proceed to the solution for the different
right hand side vectors.
using Cholseky
decomposition and then proceed to the solution for the different
right hand side vectors.